Cómo rehicimos los listados en OLX
Cuando empezamos como el equipo de Personalisation and Relevance en OLX, enfrentamos el gran desafío de migrar todos los endpoints relacionados con los listados (home feed, search y recommendations) desde una aplicación monolítica (PHP) a una arquitectura de microservicios (principalmente en Java), para tomar el control y comenzar a mejorar los listados. Más de 2 años después, lanzamos nuestra plataforma en muchos países, atendiendo ~800k solicitudes por minuto, y esto es lo que hicimos.
Analysis
Primero, hablamos con todos los stakeholders para entender qué teníamos y qué necesitábamos. En resumen, la solución debía ser:
- Fácil para lanzar nuevos algoritmos y obtener anuncios desde cualquier fuente de datos.
- Fácil para hacer pruebas A/B de esos algoritmos desde el lado del backend.
- Tolerante a fallos, de modo que ningún algoritmo sea crítico y se pueda reemplazar fácilmente por otro.
Leímos artículos publicados por otras compañías (como Pinterest, E-Bay y Amazon) para entender qué hacen otros grandes jugadores y, después de muchos borradores, llegamos a nuestra propia solución que se ajusta a nuestras necesidades.
Overview
La plataforma está compuesta principalmente por tres partes:
- Indexing: tener nuestro propio motor de búsqueda donde se indexan los anuncios.
- Retrieval: codificar los algoritmos para obtener y clasificar los anuncios desde una fuente de datos.
- Blending: combinar los algoritmos de diferentes maneras.
Indexing
Un servicio de indexación se encarga de consumir eventos desde Kafka que son publicados por el core cada vez que se crea un nuevo anuncio en la plataforma, e indexar esos anuncios en un Solr con los datos que necesitamos para realizar las búsquedas.
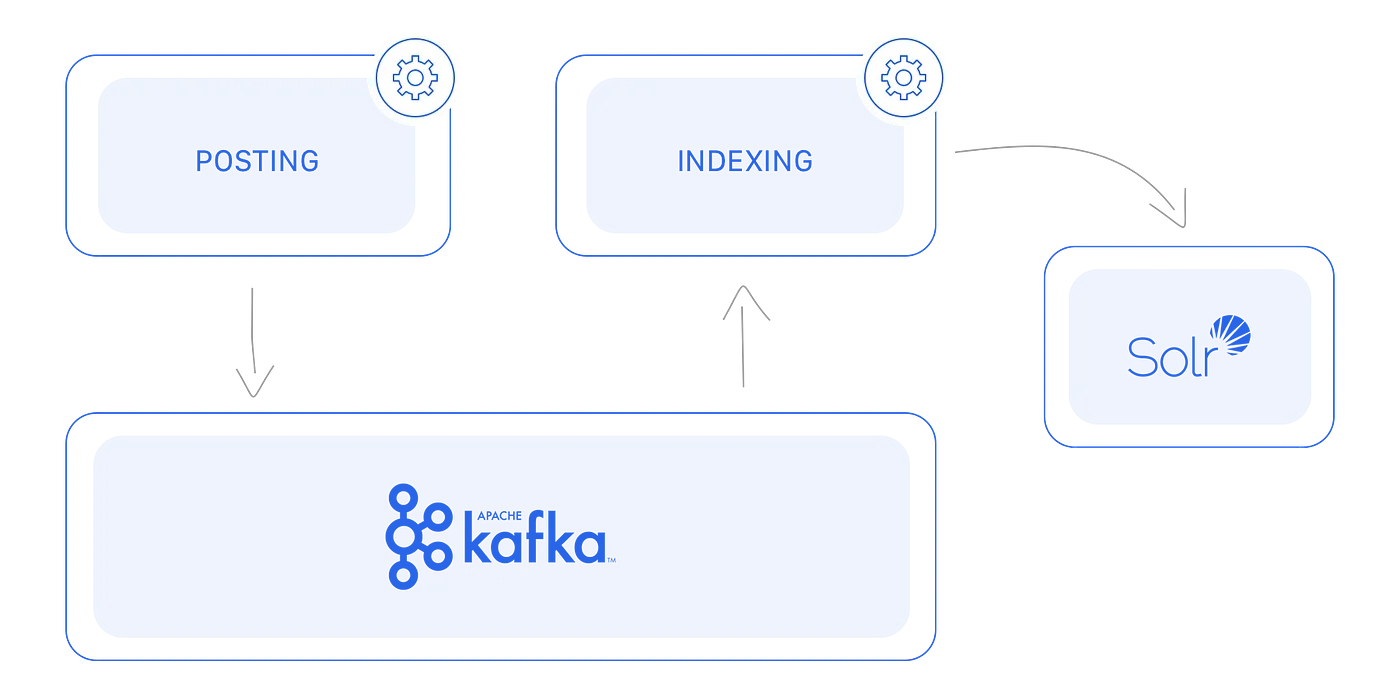
Retrieval
Otro servicio es donde codificamos los algoritmos de recuperación (principalmente consultas Solr) que obtienen y clasifican los anuncios basados en un criterio específico. Todos ellos tienen la misma interfaz, reciben parámetros específicos y devuelven una lista de anuncios clasificados (solo el ID del anuncio y un score).

Llamamos a estos algoritmos Spell. Básicamente un Spell es un fragmento de código que hace el trabajo necesario para recuperar anuncios de una fuente de datos y clasificarlos usando un criterio específico, lo que identifica al Spell. Por lo tanto, diferentes spells clasifican los anuncios de manera diferente (y podrían usar una fuente de datos distinta también).
Aunque tenemos un solo servicio para la parte de retrieval, podría dividirse en muchos servicios, por ejemplo, si se utilizan múltiples fuentes de datos o la parte de clasificación es demasiado compleja o diferente para ser parte del mismo componente. De hecho, podríamos tener spells implementados en diferentes lenguajes de programación, siempre que tengan la misma interfaz.
Blending
Se necesita un tercer servicio para combinar todos los resultados devueltos por los spells en un único conjunto de resultados, que es el listado final a devolver al usuario.
Layout
El primer componente de la parte de Blending es proporcionar una forma de configurar qué spells deben combinarse y cómo se presentan sus resultados al usuario. El enfoque inicial y simple es tener posiciones fijas (o slots) donde definimos qué Spell llena cada uno.
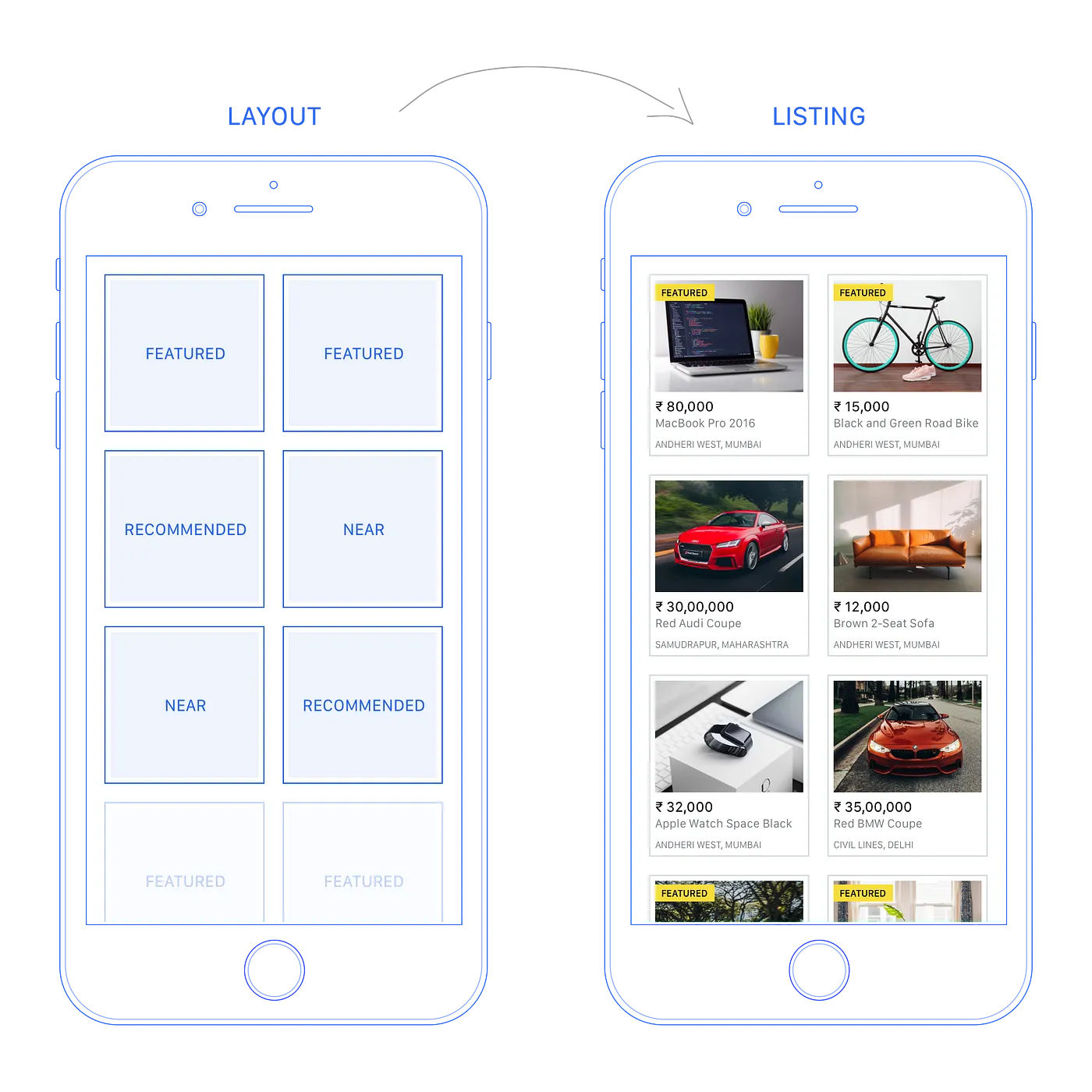
Comenzamos con 3 spells diferentes, el primero devolviendo anuncios destacados que los usuarios pagan para tener un destaque y se muestran en las primeras posiciones de cada página, el segundo encontrando recomendaciones basadas en la actividad reciente del usuario, y el último recuperando artículos que fueron publicados en ubicaciones cercanas a la posición del usuario.
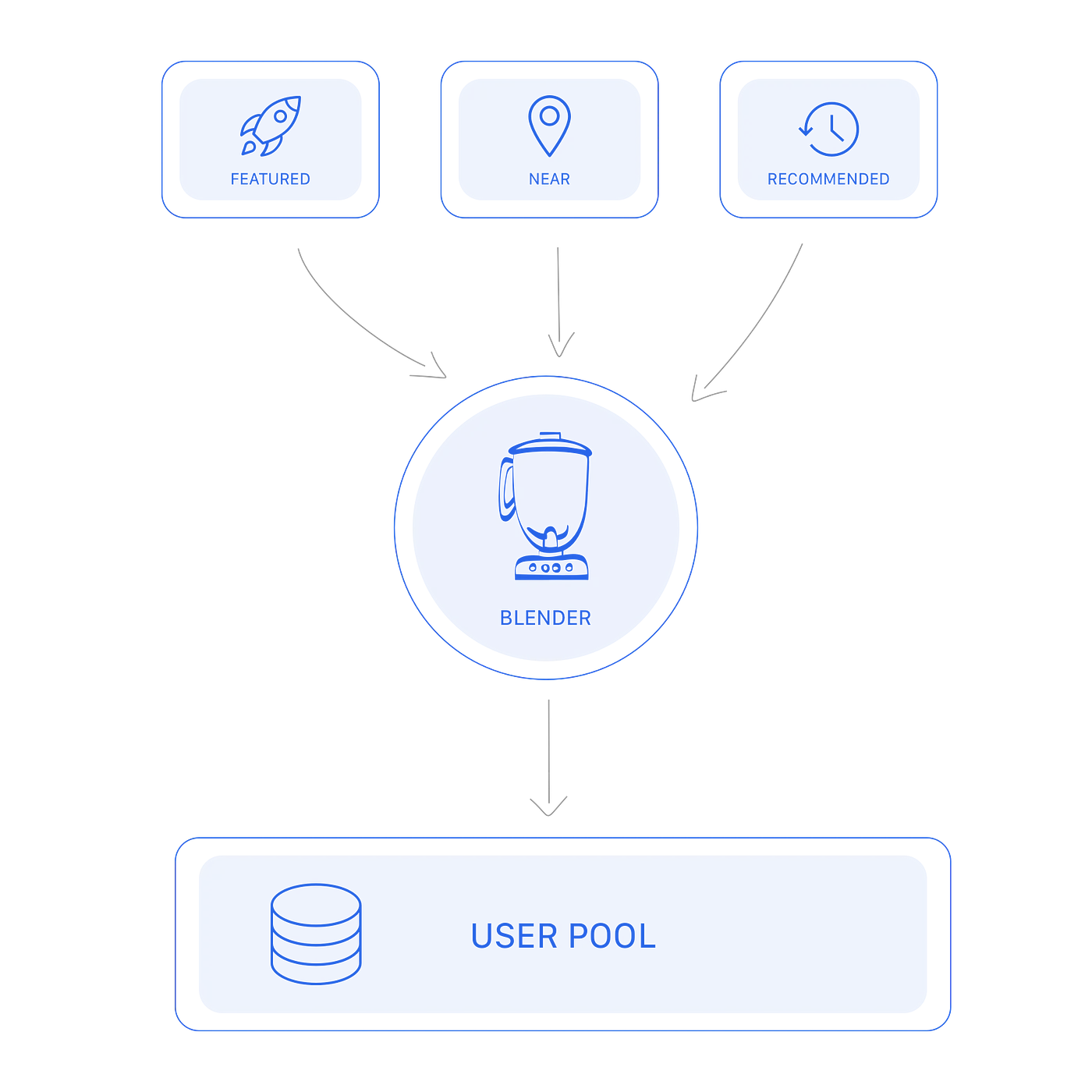
Blender
Luego, el blender en sí, que toma del layout qué spells deben ejecutarse, obtiene los resultados de cada uno en paralelo y los combina según la configuración definida en el diseño. El blender no se preocupa por lo que hace cada Spell, por lo que todos los parámetros recibidos del cliente se reenvían a los spells sin modificación alguna.
La tolerancia a fallos es fundamental en este proceso, ya que algunos spells podrían fallar o simplemente no devolver resultados para una solicitud específica. El blender debe manejar estas excepciones. Una de las cosas que hace es tener un fallback, que es básicamente otro Spell (generalmente más simple y confiable) de donde puede obtener resultados en caso de fallos o resultados vacíos del original. Otra es usar disyuntores (circuit breakers), de modo que cuando un hechizo falla continuamente, se quita del proceso de blending hasta que se recupere.
User Pool
Después de que el blender genera el conjunto final de resultados, guardamos todos los resultados para el usuario, de modo que la paginación se haga sobre esta estructura en lugar de hacer todo este proceso cada vez que el usuario solicite una nueva página. Básicamente, generamos el listado completo (todas las páginas que el usuario podría necesitar) cuando se solicita la primera página, y después de eso obtenemos los resultados directamente del pool de usuarios en las páginas siguientes, hasta que el cliente solicite la primera página nuevamente o el pool de usuarios expire (generalmente después de 1 hora).
Detrás de escena, los pools de usuarios son Sorted Sets en Redis, donde solo ponemos los IDs de los anuncios y sus scores. Dado que esto se implementa en memoria y tenemos un pool para cada usuario, es fundamental establecer una expiración para ser eficientes en el uso de recursos.
Hydration
Finalmente, dado que hasta ahora solo estábamos utilizando los IDs de los anuncios, necesitamos obtener los datos de cada anuncio desde otro servicio para devolverlos a los frontends (PWA, Android y iOS) para que puedan hacer la parte de presentación en pantalla. Estos anuncios se almacenan en una base de datos MySQL del servicio core, por lo que se agregó una capa de caché (Redis) para tener acceso más rápido a estos datos.
Embebed A/B Testing tool
Desde el principio pensamos la plataforma para entregar y medir fácilmente nuevas funcionalidades a nuestros usuarios. Es por eso que nuestro componente blender es totalmente testeable con pruebas A/B, para que podamos probar diferentes spells o estrategias de combinación sin cambiar la interfaz, y de esta forma, no requerir cambios de frontend.
Dividimos a los usuarios en función de sus IDs y les asignamos un layout, midiendo qué configuración tiene mejor rendimiento.
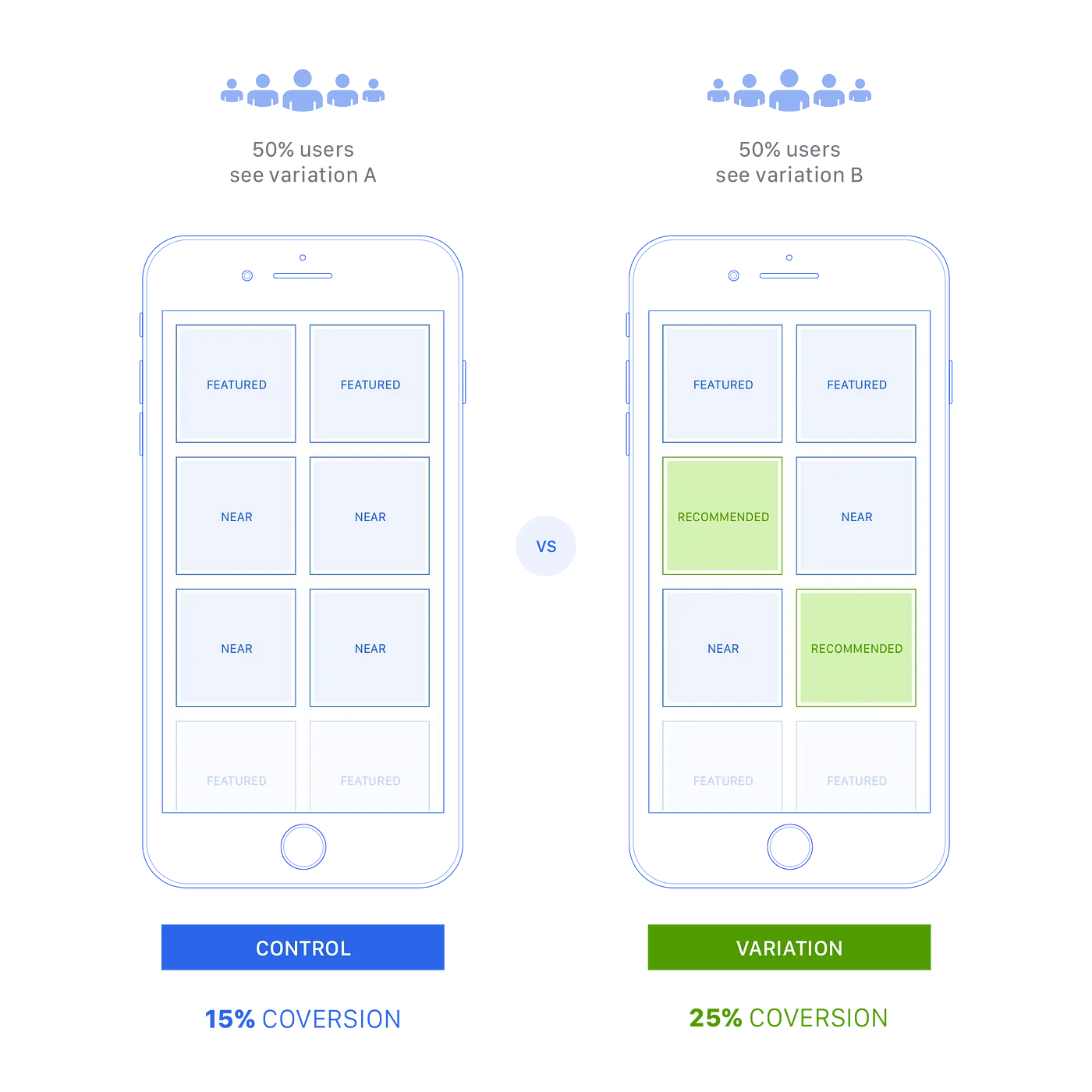
Hemos probado y combinado más de 30 spells en nuestros listados, y uno de los más exitosos en términos de conversión, fue desarrollado por otro equipo que lo hizo para una plataforma y mercado diferente, pero se integró fácilmente con la nuestra gracias a esta arquitectura.
Conclusión
Aún seguimos agregando nuevos spells y mejorando las estrategias de combinación, creamos una arquitectura que nos permitió validar hipótesis y entregar valor a nuestros usuarios muy rápidamente, trabajando junto con personas de todo el mundo para lograr el mismo objetivo: mostrar a los usuarios lo que quieren ver.